Learning new robot tasks on new platforms and in new scenes from only a handful of demonstrations remains challenging. While videos of other embodiments—humans and different robots—are abundant, differences in embodiment, camera, and environment hinder their direct use. We address this small-data problem by introducing a unifying, symbolic representation: a compact 3D “trace-space” of scene-level trajectories that enables learning from cross-embodiment, cross-environment, and cross-task videos. We present TraceGen, a world model that predicts future motion in trace-space rather than pixel space, abstracting away appearance while retaining the geometric structure needed for manipulation. To train TraceGen at scale, we develop TraceForge, a data pipeline that transforms heterogeneous human and robot videos into consistent 3D traces, yielding a corpus of 123K videos and 1.8M observation–trace–language triplets. Pretraining on this corpus produces a transferable 3D motion prior that adapts efficiently: with just five target robot videos, TraceGen attains 80% success across four tasks while offering 50–600× faster inference than state-of-the-art video-based world models. In the more challenging case where only five uncalibrated human demonstration videos captured on a handheld phone are available, it still reaches 67.5% success on a real robot, highlighting TraceGen’s ability to adapt across embodiments without relying on object detectors or heavy pixel-space generation.
"Open the drawer"
"Drop the LEGO block in the drawer"
"Close the drawer"
Unified 3D trace
Robot execution with the unified 3D trace
Task 1: Folding a garment (Clothes)
Task 2: Inserting a tennis ball into a box (Ball)
Task 3: Sweeping trash into a dustpan with a brush (Brush)
Task 4: Placing a LEGO block in the purple region (Block)
Our dataset (TraceForge-123K) consists of a diverse set of skills and embodiments.
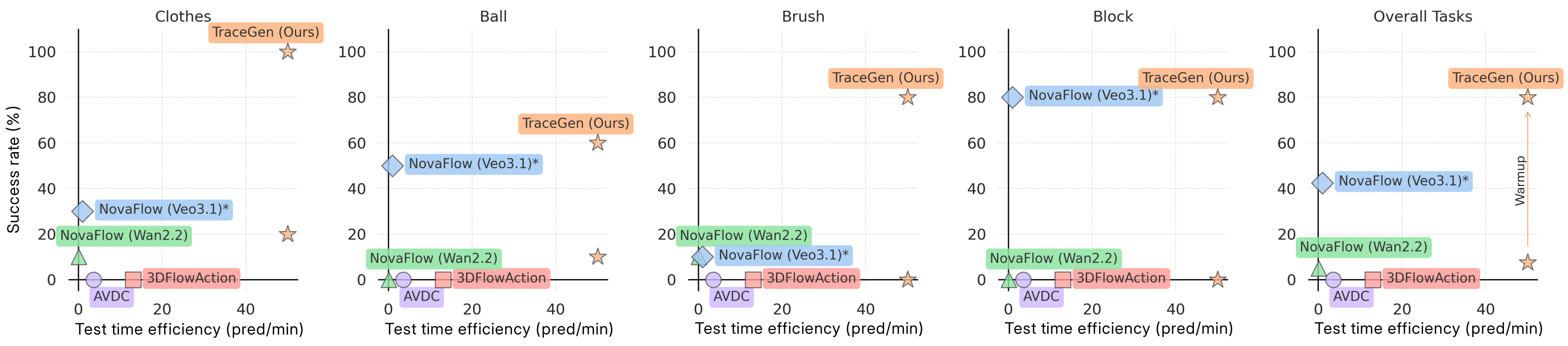
Success rate vs. inference efficiency (predictions per minute; higher and rightward is better). TraceGen achieves the best combination of success and efficiency, outperforming both video and trace-based baselines by a large margin.
Generated video (Wan 2.2): Hallucinated embodiment.
Generated video (Veo 3.1): Not physically grounded.
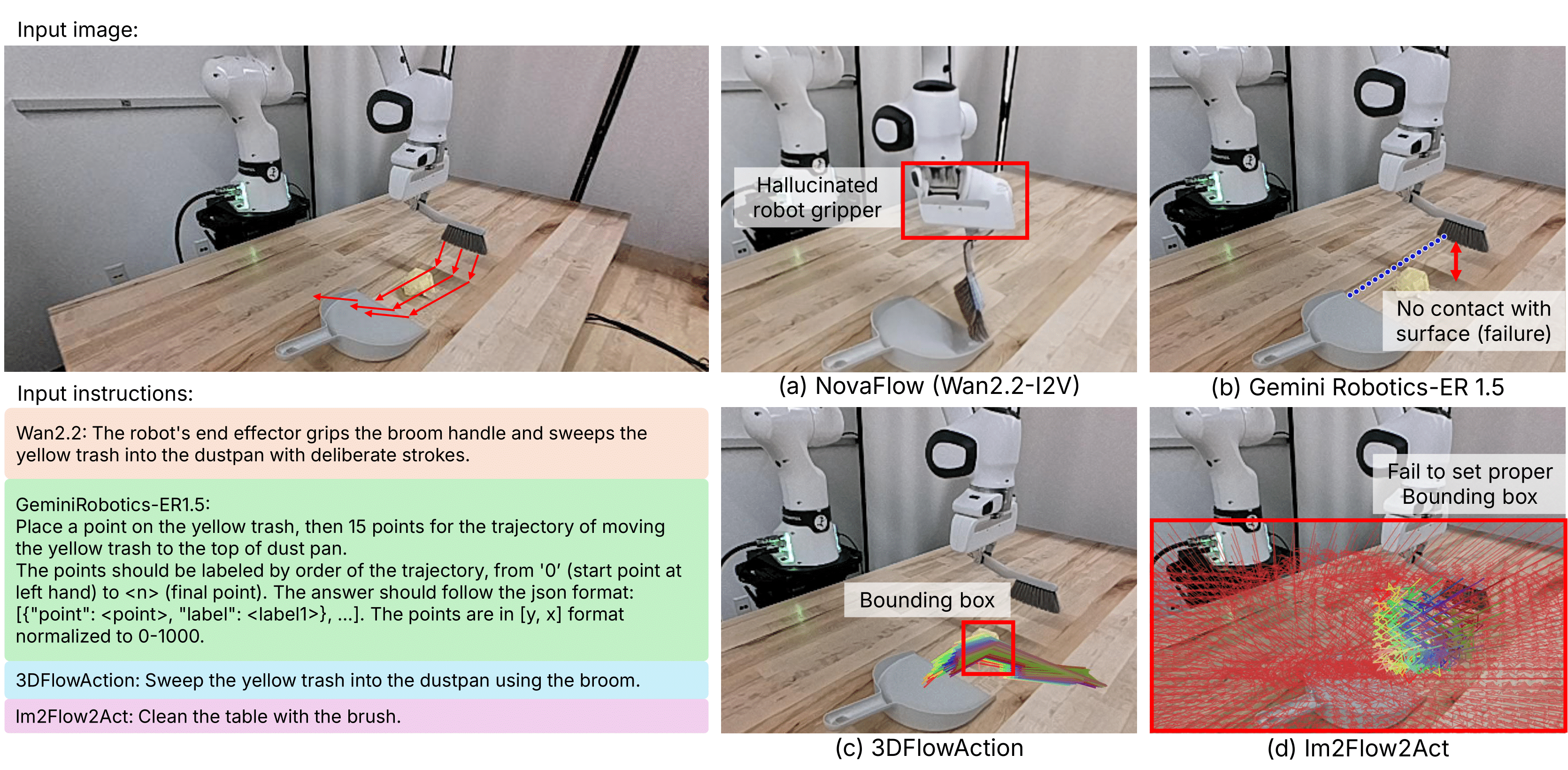
Failure cases of existing embodied world models.
(a) NovaFlow (Wan2.2-I2V): Video-based
models can hallucinate geometry or affordance.
(b) Gemini Robotics-ER 1.5: VLM token outputs fail to capture fine motion.
(c) 3DFlowAction: Bounding boxes miss the
tool.
(d) Im2Flow2Act: Bounding boxes become
overly broad.
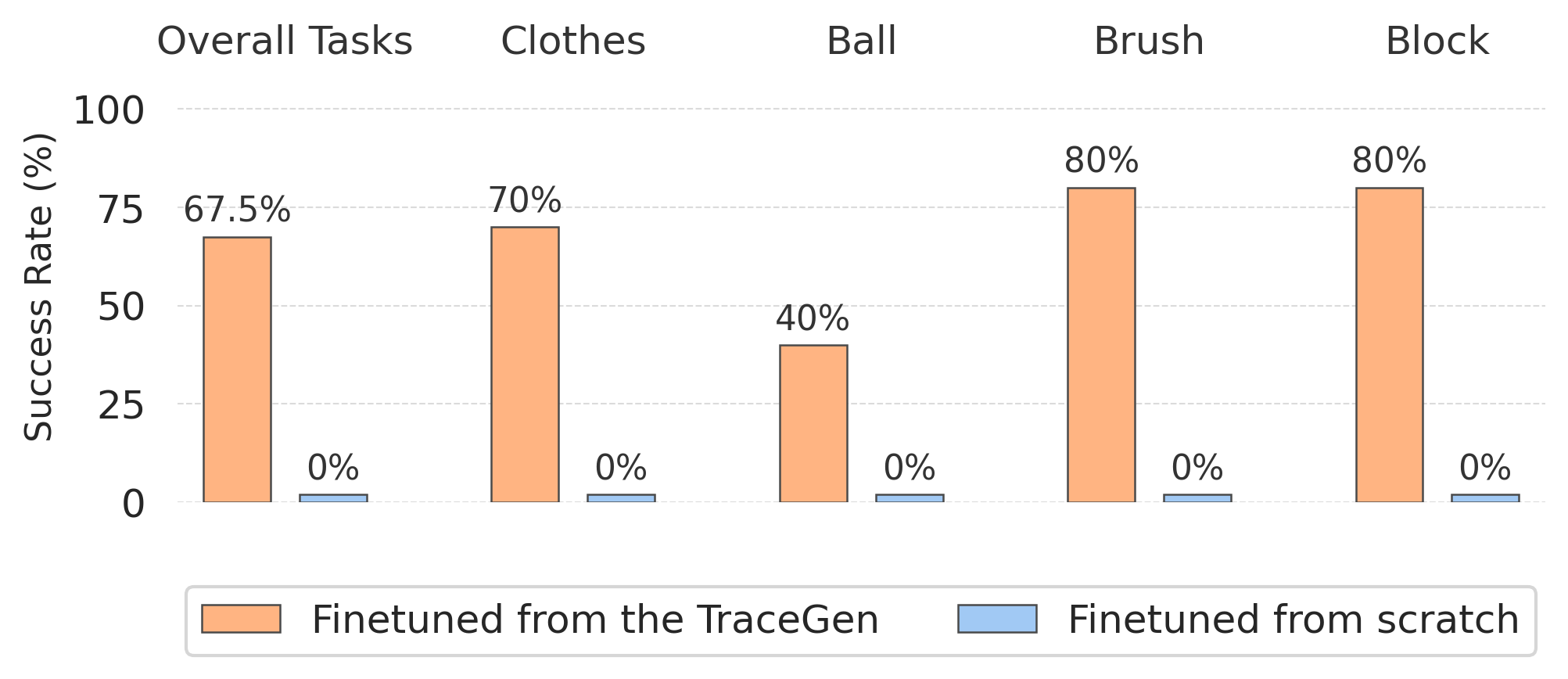
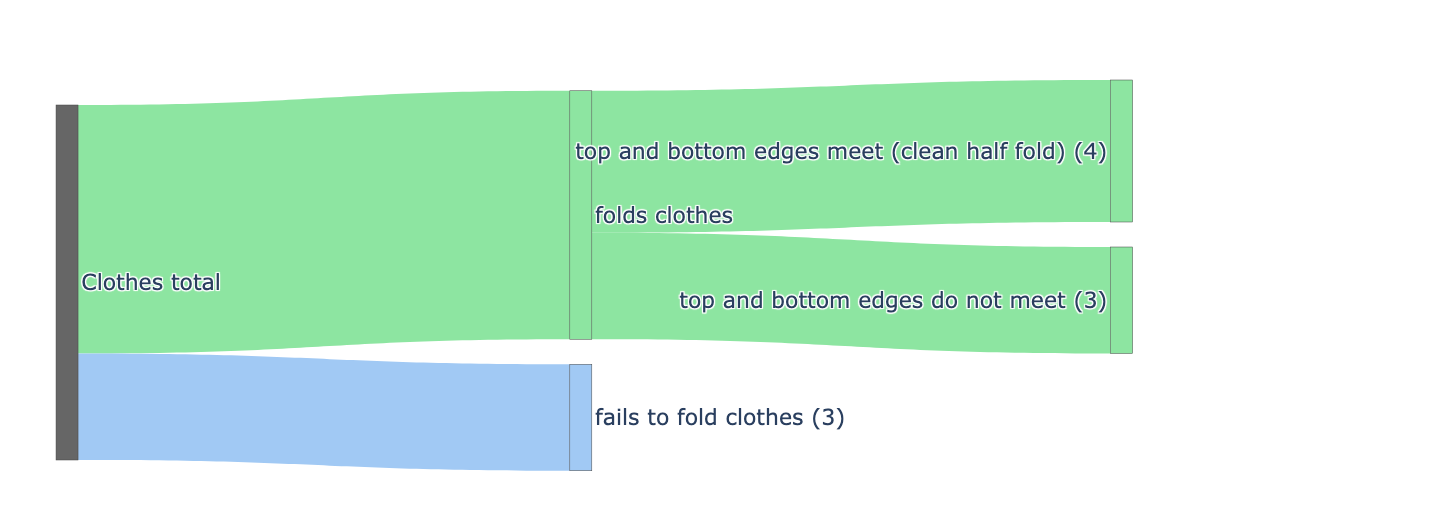
Human-to-robot skill transfer using human demo videos. TraceGen, finetuned on 5 in-the-wild handheld phone videos, successfully executes four manipulation tasks with a success rate of 67.5%.
| Warm-up | Pretraining | Clothes | Ball | Brush | Block | Overall SR (%) |
|---|---|---|---|---|---|---|
| 5 robot videos | Random init. | 10/10 | 0/10 | 0/10 | 0/10 | 25.0% |
| TraceGen | 10/10 | 6/10 | 8/10 | 8/10 | 80% | |
| 15 robot videos | Random init. | 10/10 | 0/10 | 0/10 | 2/10 | 30.0% |
| TraceGen | 10/10 | 9/10 | 8/10 | 6/10 | 82.5% |
| Task | From scratch | SSV2 only | Agibot only | TraceForge-123K |
|---|---|---|---|---|
| Ball | 0/10 | 3/10 | 4/10 | 6/10 |
| Block | 0/10 | 2/10 | 5/10 | 8/10 |
| Overall SR (%) | 0% | 25% | 45% | 70% |
@article{lee2025tracegen,
title={TraceGen: World Modeling in 3D Trace Space Enables Learning from Cross-Embodiment Videos},
author={Lee, Seungjae and Jung, Yoonkyo and Chun, Inkook and Lee, Yao-Chih and Cai, Zikui and Huang, Hongjia and Talreja, Aayush and Dao, Tan Dat and Liang, Yongyuan and Huang, Jia-Bin and Huang, Furong},
journal={arXiv preprint arXiv:2511.21690},
year={2025}
}